Von gefühlsbasierten Bewertungen zu systematischen Tests
Mit Lovable und einem Helfer wie ChatGPT ist es jetzt einfach, ein KI-natives Produkt schnell aufzusetzen. Sie sprechen mit Nutzern, erfassen die schmerzhaften Punkte, übertragen die Notizen in Miro und lassen die Clustering-Funktion von Miro Themen und Stimmungen sortieren. Dann skizzieren Sie ein paar Lösungsansätze, lassen ChatGPT eine Spezifikation entwerfen und Lovable einen funktionierenden Prototyp zusammenstellen. Tech-Gründer hatten es noch nie so einfach, nutzerzentrierte, schlanke und kostengünstige MVPs zu erstellen.
Da die Gründerin von Future Habits, Kasia Sadowska, auch einen Startup-Beschleuniger mit dem Founder Institute leitet, hört sie Sätze wie „Mein Mentor sagte, ich brauche KI in meinem Produkt, um Geld zu beschaffen“ oder „Investoren schauen sich nur Produkte mit KI an“. Gründer fügen KI oft nur hinzu, um ein Kästchen abzuhaken. Wenn Sie Modellfunktionen nur aus diesem Grund hinzugefügt haben, helfen wir Ihnen, dass sie sich auch bezahlt machen. Verfolgen Sie, wie die Leute sie tatsächlich nutzen. Welche Funktionen helfen, welche verwirren und wo eine menschliche Übergabe sinnvoll wäre.
Dieser Beitrag zeigt Ihnen den Weg von Gefühlschecks zu echten Evaluierungen für Lovable-Builds.
Was Evals sind
Evals sind strukturierte Tests für das Modellverhalten. Stellen Sie sie sich als Unit-Tests und Quality Gates für Ihr Produkt vor, die an wichtige Ergebnisse gekoppelt sind. Sie beantworten die Frage „Erfüllt dies unsere Anforderungen?“, bevor Sie das Produkt veröffentlichen.
Warum jetzt? Rapid Prototyping bringt probabilistische Ergebnisse, wechselnde Modellversionen und hohe Nutzererwartungen an die Konsistenz mit sich. Evals definieren, was „gut“ ist, und prüfen dies dann automatisch.
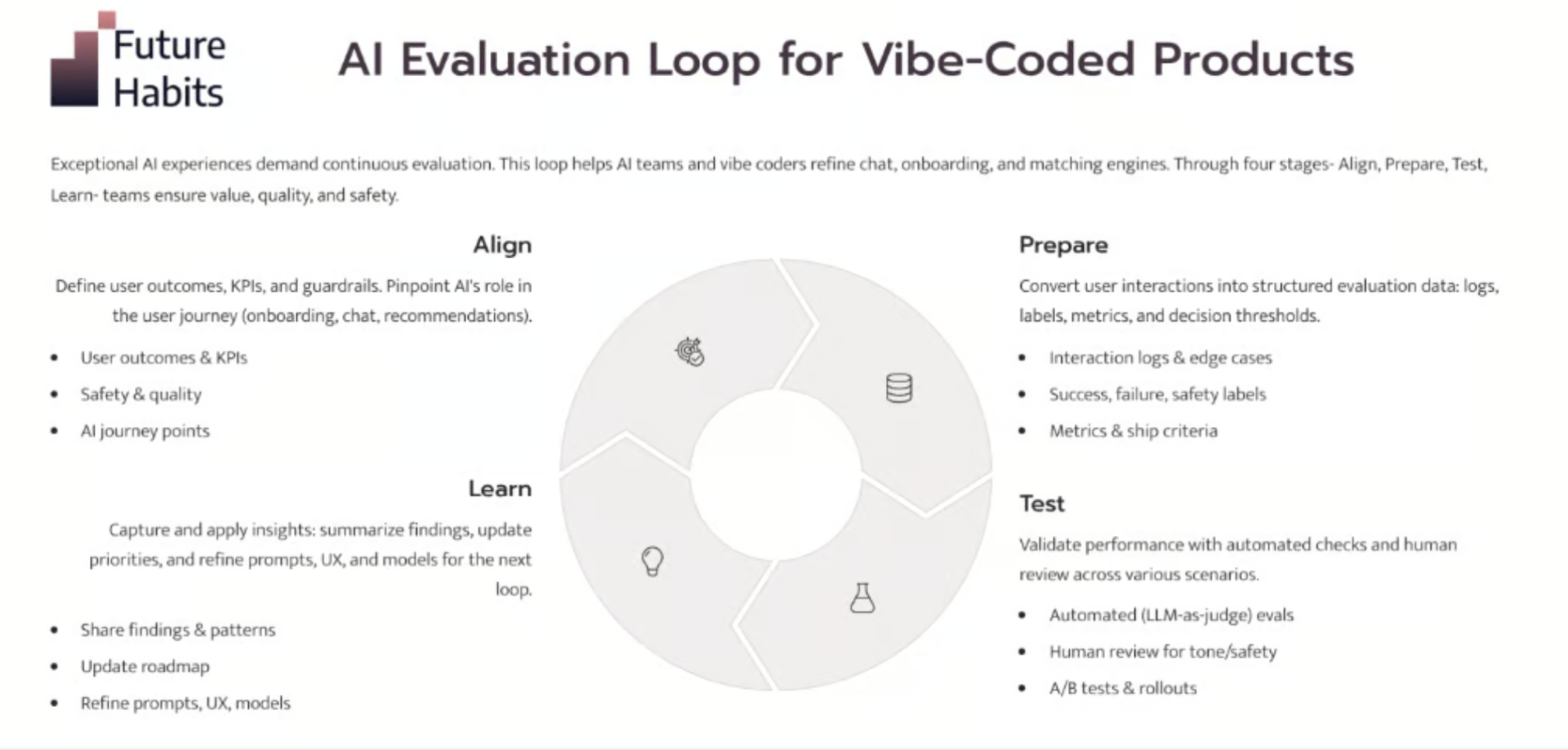
Das 3-Phasen-Framework
Phase 1: In der Realität verankern. Studieren Sie zuerst die reale Nutzung. Ziehen Sie etwa 100 repräsentative Traces, kennzeichnen Sie Erfolge und Misserfolge und erstellen Sie durch offenes und axiales Codieren mit einem einzigen Domain-Entscheider, dem wohlwollenden Diktator, eine einfache Liste von Fehlermodi.
Phase 2: Zuverlässige Evals erstellen. Verwenden Sie Code-Prüfungen für objektive Fehler und ein LLM als Bewerter für subjektive Qualität. Validieren Sie Ihren Bewerter anhand menschlicher Ground-Truth-Daten und messen Sie die Rate der richtig Positiven (True Positive Rate) und die Rate der richtig Negativen (True Negative Rate), nicht nur die Genauigkeit.
Phase 3: Operationalisieren. Führen Sie Evals bei jeder Änderung von Prompts, Modellen oder Architekturen durch, überwachen Sie sie in der Produktion und speisen Sie Fehler zurück in die Produktarbeit. So entsteht ein kontinuierlicher Verbesserungszyklus.
Was Sie messen
Verknüpfen Sie Modellprüfungen mit Geschäftsergebnissen, damit sie für das Team relevant sind. Beispiele sind die Eskalationsgenauigkeit zur Reduzierung des Supportaufwands, die Hilfsbereitschaft zur Steigerung der Zufriedenheit, die Halluzinationsrate zum Schutz des Vertrauens, die mehrsprachige Genauigkeit zur Erschließung neuer Märkte und die Lösungsrate zur Reduzierung der Abwanderung. Legen Sie für jede Metrik klare Schwellenwerte fest.
Decken Sie fünf Metrikgruppen ab: Leistungsfähigkeit, Sicherheit, Benutzererfahrung, Zuverlässigkeit und Effizienz. Für die Effizienz sollten Sie Latenz, Kosten pro Anfrage und Token-Nutzung verfolgen.
Lovable-Besonderheiten, die Teams vor Herausforderungen stellen
Lovable-Anwendungen ändern sich schnell und enthalten oft mehrere Modellkomponenten. Testen Sie auf vier Ebenen: Prompt, Komponente, End-to-End-Flows und Live-Monitoring. Fügen Sie leichtgewichtiges Logging in Komponenten hinzu, senden Sie Traces an Ihren Eval-Service und lassen Sie sich benachrichtigen, wenn die Qualität nachlässt.
Ein minimales Muster sieht so aus: Traces auf dem Client protokollieren, einen Webhook auslösen, der eine rollierende Stichprobe auswertet, Erfolg oder Misserfolg aufzeichnen und benachrichtigen, wenn sich die Fehlerraten ändern. Wenn Sie LangChain unter der Haube verwenden, hilft LangSmith beim Tracing von Chains.
Häufige Fallen und Lösungen
- Gefühl statt Fakten. Verzichten Sie auf oberflächliche Dashboards. Beginnen Sie mit der Fehleranalyse von echten Traces und verknüpfen Sie jede Metrik mit dem Nutzerwert.
- Genauigkeits-Theater. Genauigkeit verbirgt bei unausgewogenen Datensätzen, was wirklich zählt. Verfolgen Sie die Raten der richtig Positiven und richtig Negativen sowie die Kosten jedes Fehlers.
- Unkalibrierte Bewerter. Erstellen Sie zuerst einen kleinen Ground-Truth-Datensatz, optimieren Sie dann Ihren LLM-Bewerter und testen Sie ihn an einem zurückgehaltenen Datensatz.
- Veraltete Eval-Suites. Entfernen Sie Tests, die nie fehlschlagen, und fügen Sie neue hinzu, wenn sich die Fehlermodi ändern. Überprüfen Sie dies monatlich.
- Testen mit nur einer Methode. Kombinieren Sie Code-Prüfungen für deterministische Fehler mit LLM-Bewertungen für Ton, Klarheit und Relevanz.
- Fehlende Workflow-Integration. Integrieren Sie Evals in CI, blockieren Sie Merges, die kritische Prüfungen nicht bestehen, und nehmen Sie kontinuierlich Stichproben aus der Produktion.
Tools, die gut zusammenspielen
Wählen Sie einen kleinen Stack. Wählen Sie für den Anfang ein Tool aus jeder Gruppe.
- Evals und Test-Harnesses — OpenAI Evals mit Python-Templates, DeepEval, promptfoo, Ragas für Retrieval-Prüfungen, TruLens für Feedback-Funktionen
- Tracing und Observability — LangSmith, Langfuse, OpenTelemetry für LLMs, Arize Phoenix für Fehleranalysen im Notebook-Stil
- Experimente und Feature Flags — Statsig, LaunchDarkly oder ein einfacher Canary mit GitHub Actions
- Daten und Labeling — Label Studio für leichtgewichtiges Labeling, synthetische Testdaten mit Mostly AI oder Gretel, wenn Datenschutz wichtig ist
- Regressionskontrolle und CI — GitHub Actions, GitLab CI oder CircleCI, um Evals bei jedem Pull Request auszuführen, mit Validatoren wie Guardrails AI oder pydantic
- Kosten- und Latenz-Tracking — Nutzungsprotokolle von Ihrem Modellanbieter, plus Evidently AI oder WhyLabs für Drift- und Performance-Prüfungen
- Prompt-Management, optional — Weights and Biases Prompts, PromptLayer für Verlauf und schnelle Vergleiche
Bei FutureHabits.Tech
Bei FutureHabits.tech helfen wir Teams, Modellfunktionen in messbare Ergebnisse umzuwandeln. Wir beginnen mit Ihren echten Nutzer-Traces, definieren klare Regeln für Erfolg und Misserfolg und verbinden Evals mit Ihrer Build-Pipeline. Die Qualität verbessert sich mit jeder Veröffentlichung, nicht nur jedes Quartal.
Was wir liefern:
- Schnell skalieren, ohne die Qualität zu beeinträchtigen. Liefern Sie hinter Flags aus, führen Sie Evals bei jedem Pull Request aus und fangen Sie Regressionen ab, bevor es die Nutzer tun.
- Kosten im Griff behalten. Verfolgen Sie Latenz, Token-Nutzung und Trefferquote für jede Funktion. Entfernen oder überdenken Sie alles, was kein klares Ergebnis erzielt.
Bereit, Ihr Produkt auf klare Metriken und ein schlankes Kostenprofil auszurichten? Kontaktieren Sie uns. Wir machen Ihre KI-Funktionen messbar, Ihre Releases sicherer und Ihre Kosten pro Ergebnis gesünder, damit Sie schnell und fokussiert skalieren können.