Przejdź od ocen opartych na odczuciach do systematycznego testowania
Stworzenie natywnego produktu AI z Lovable i asystentem takim jak ChatGPT jest teraz proste. Rozmawiasz z użytkownikami, wychwytujesz bolesne punkty, wrzucasz notatki do Miro i pozwalasz, aby klastrowanie Miro posortowało tematy i sentymenty. Następnie szkicujesz kilka możliwych rozwiązań, prosisz ChatGPT o przygotowanie specyfikacji i pozwalasz Lovable złożyć działający prototyp. Founderzy technologiczni nigdy nie mieli łatwiejszego zadania w budowaniu zorientowanych na użytkownika, oszczędnych i tanich MVP.
Ponieważ Kasia Sadowska, założycielka Future Habits, prowadzi również akcelerator startupów z Founder Institute, często słyszy zdania takie jak: „Mój mentor powiedział, że potrzebuję AI w produkcie, aby pozyskać finansowanie” lub „Inwestorzy patrzą tylko na produkty z AI”. Founderzy często dodają AI tylko po to, by odhaczyć punkt na liście. Jeśli dodałeś funkcje modelu tylko dla zasady, pomóżmy im na siebie zapracować. Śledź, jak ludzie faktycznie z nich korzystają. Które funkcje pomagają, które wprowadzają w błąd i gdzie przydałoby się wsparcie człowieka.
Ten artykuł to Twoja ścieżka od sprawdzania „na wyczucie” do prawdziwych ewaluacji dla produktów tworzonych w Lovable.
Czym są ewaluacje
Ewaluacje to ustrukturyzowane testy zachowania modelu. Myśl o nich jak o testach jednostkowych i bramkach jakości dla Twojego produktu, powiązanych z istotnymi wynikami. Odpowiadają na pytanie: „Czy to spełnia nasze standardy?” zanim wypuścisz produkt na rynek.
Dlaczego teraz? Szybkie prototypowanie przynosi probabilistyczne wyniki, zmieniające się wersje modeli i wysokie oczekiwania użytkowników co do spójności. Ewaluacje definiują, co jest „dobre”, a następnie sprawdzają to automatycznie.
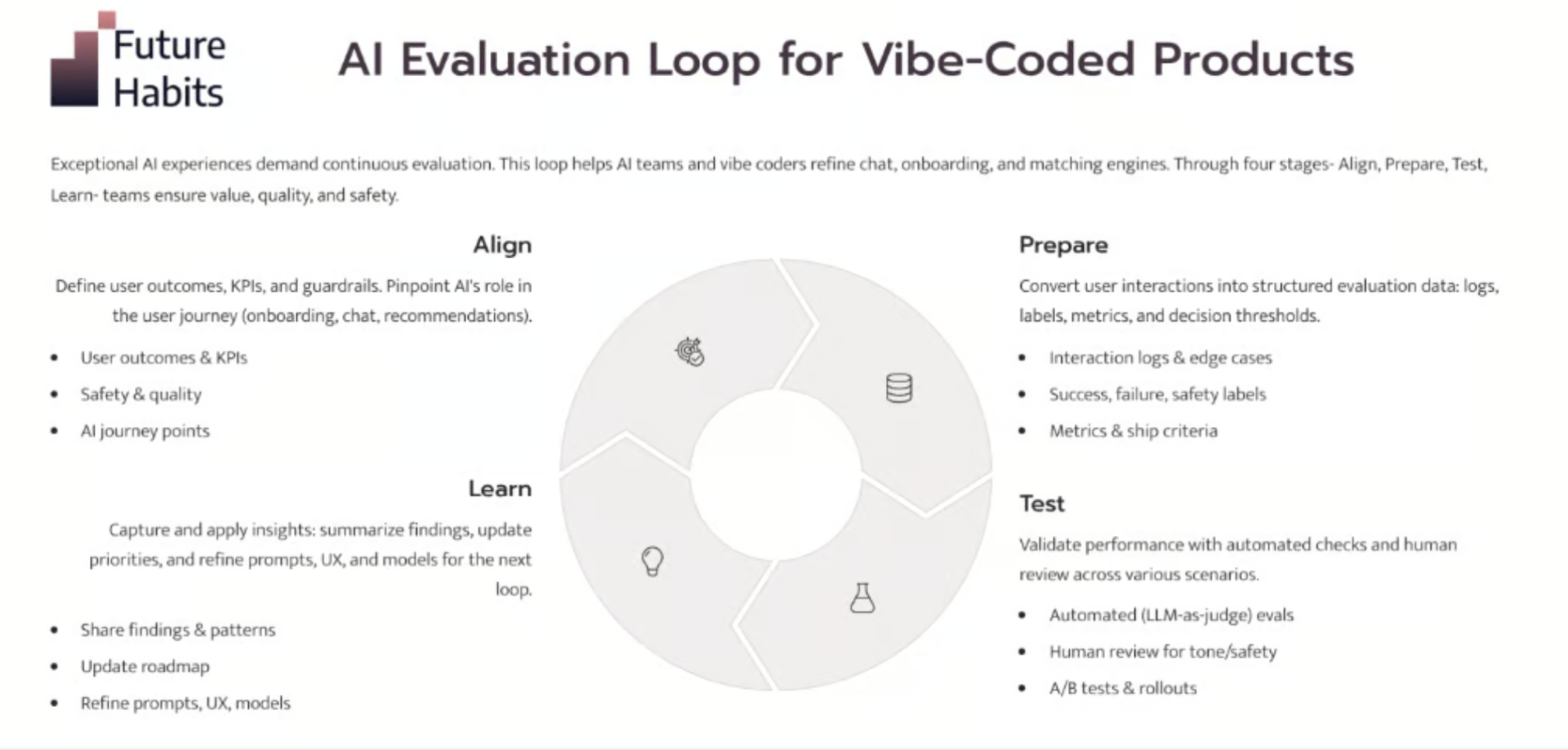
3-fazowy framework
Faza 1: Ugruntowanie w rzeczywistości. Najpierw przeanalizuj rzeczywiste użycie. Zbierz około 100 reprezentatywnych śladów (traces), oznacz sukcesy i porażki, a następnie stwórz prostą listę trybów awarii poprzez kodowanie otwarte i osiowe z jednym decydentem dziedzinowym – życzliwym dyktatorem.
Faza 2: Budowanie wiarygodnych ewaluacji. Użyj testów opartych na kodzie do obiektywnych błędów i LLM-as-judge (LLM jako sędzia) do subiektywnej oceny jakości. Zweryfikuj swojego „sędziego” na podstawie ludzkiej oceny (ground truth) i mierz wskaźnik prawdziwie pozytywny (true positive rate) oraz prawdziwie negatywny (true negative rate), a nie tylko dokładność.
Faza 3: Operacjonalizacja. Uruchamiaj ewaluacje przy każdej zmianie promptu, modelu lub architektury, monitoruj w środowisku produkcyjnym i przekazuj informacje o awariach z powrotem do prac nad produktem. Tworzy to pętlę ciągłego doskonalenia.
Co mierzyć
Powiąż testy modelu z wynikami biznesowymi, aby zespół się nimi przejmował. Przykłady obejmują dokładność eskalacji w celu zmniejszenia obciążenia wsparcia, pomocność w celu zwiększenia satysfakcji, wskaźnik halucynacji w celu ochrony zaufania, dokładność wielojęzyczną w celu dotarcia na nowe rynki oraz wskaźnik rozwiązania problemu w celu zmniejszenia churnu. Ustal jasne progi dla każdego z nich.
Obejmij pięć grup metryk: zdolności (capability), bezpieczeństwo, doświadczenie użytkownika (user experience), niezawodność i wydajność. W przypadku wydajności śledź opóźnienia, koszt zapytania i zużycie tokenów.
Specyfika Lovable, która sprawia zespołom problemy
Aplikacje Lovable szybko się zmieniają i często zawierają kilka komponentów modelu. Testuj na czterech poziomach: prompt, komponent, przepływy end-to-end i monitorowanie na żywo. Dodaj lekkie logowanie w komponentach, przesyłaj ślady (traces) do swojego serwisu ewaluacyjnego i ustawiaj alerty, gdy jakość spada.
Minimalny wzorzec wygląda następująco: loguj ślady po stronie klienta, wyzwalaj webhook, który ocenia próbkę kroczącą, zapisuj wynik pozytywny lub negatywny i powiadamiaj, gdy wskaźniki błędów rosną. Jeśli pod spodem używasz LangChain, LangSmith pomaga śledzić łańcuchy (chains).
Częste pułapki i rozwiązania
- Odczucia ponad dowodami. Unikaj próżnych dashboardów. Zacznij od analizy błędów na rzeczywistych śladach i powiąż każdą metrykę z wartością dla użytkownika.
- Teatr dokładności. Dokładność ukrywa to, co istotne w niezbalansowanych zbiorach. Śledź wskaźniki prawdziwie pozytywne i prawdziwie negatywne oraz koszt każdego błędu.
- Nieskalibrowani sędziowie. Najpierw zbuduj mały zbiór referencyjny (ground-truth), a następnie dostrój swojego sędziego LLM i przetestuj go na zestawie walidacyjnym (held-out set).
- Nieaktualne zestawy ewaluacyjne. Wycofuj testy, które nigdy nie zawodzą, i dodawaj nowe, gdy zmieniają się tryby awarii. Przeglądaj je co miesiąc.
- Testowanie jedną metodą. Łącz testy oparte na kodzie dla błędów deterministycznych z oceną LLM pod kątem tonu, jasności i trafności.
- Brak integracji z przepływem pracy. Umieść ewaluacje w CI, blokuj merge, które nie przechodzą krytycznych testów, i stale próbkuj dane z produkcji.
Narzędzia, które dobrze ze sobą współpracują
Wybierz mały stos technologiczny. Na początek wybierz po jednym narzędziu z każdej grupy.
- Ewaluacje i uprzęże testowe (test harnesses) — OpenAI Evals z szablonami Python, DeepEval, promptfoo, Ragas do testów retrievalu, TruLens do funkcji feedbacku
- Śledzenie i obserwowalność (observability) — LangSmith, Langfuse, OpenTelemetry dla LLM, Arize Phoenix do analizy błędów w stylu notatnika
- Eksperymentacja i flagi funkcyjne (feature flags) — Statsig, LaunchDarkly, lub prosty canary na GitHub Actions
- Dane i etykietowanie — Label Studio do lekkiego etykietowania, syntetyczne dane testowe z Mostly AI lub Gretel, gdy prywatność ma znaczenie
- Kontrola regresji i CI — GitHub Actions, GitLab CI, lub CircleCI do uruchamiania ewaluacji przy każdym pull requeście, z walidatorami takimi jak Guardrails AI lub pydantic
- Śledzenie kosztów i opóźnień — Logi użycia od dostawcy modelu, plus Evidently AI lub WhyLabs do sprawdzania dryftu i wydajności
- Zarządzanie promptami, opcjonalne — Weights and Biases Prompts, PromptLayer do historii i szybkich porównań
W FutureHabits.Tech
W FutureHabits.tech pomagamy zespołom przekształcać funkcje modelu w mierzalne wyniki. Zaczynamy od rzeczywistych śladów użytkowników, definiujemy jasne zasady zaliczenia i niezaliczenia oraz łączymy ewaluacje z Twoim potokiem deweloperskim (build pipeline). Jakość poprawia się z każdym wydaniem, a nie tylko co kwartał.
Co dostarczamy:
- Szybko skaluj bez utraty jakości. Wdrażaj funkcje za flagami, uruchamiaj ewaluacje przy każdym pull requeście i wychwytuj regresje, zanim zrobią to użytkownicy.
- Utrzymuj koszty pod kontrolą. Śledź opóźnienia, zużycie tokenów i wskaźnik trafień (hit rate) dla każdej funkcji. Usuwaj lub przemyśl wszystko, co nie przynosi wyraźnego rezultatu.
Gotowy, by połączyć swój produkt z jasnymi metrykami i oszczędnym profilem kosztowym? Skontaktuj się z nami. Sprawimy, że Twoje funkcje AI będą mierzalne, wydania bezpieczniejsze, a koszt na wynik zdrowszy, dzięki czemu możesz skalować się szybko i z koncentracją.